Qwen3-Omni | مدل omni-modal Alibaba با پردازش متن، تصویر، صوت و ویدیو
به گفته hackster
معرفی و جایگاه Qwen3-Omni
Alibaba Cloud تازهترین عضو خانواده مدلهای زبانی بزرگ Qwen (Tongyu Qianwen) را معرفی کرده است: Qwen3-Omni. ادعای اصلی، «natively end-to-end multilingual omni-modal» است؛ یعنی یک مدل واحد که ورودیهای متن، تصویر، صوت و ویدیو را میپذیرد و میتواند خروجی متن و گفتار استریمی ارائه کند. هر سه نسخه منتشرشده 30 میلیارد پارامتر دارند.
بهگفتهی Xiong Wang از Alibaba Cloud، هدف طراحی Qwen3-Omni پردازش ورودیهای متنوع و ارائه پاسخهای بیدرنگ در قالب متن و گفتار طبیعی است. تمرکز ویژهای نیز بر کاهش تأخیر بهمنظور تعاملات صوتمحور شده است.
برای زمینهسازی، یادآوری میشود LLMها مدلهای آماریاند که با بلعیدن دادههای عظیم و تبدیل آنها به «توکن»ها، دنبالهای از توکنهای محتمل را در پاسخ به ورودی تولید میکنند. کیفیت پاسخ وقتی مطلوب است که «شکل پاسخ» با واقعیت منطبق باشد؛ در غیر این صورت، پاسخ تنها از نظر شکل شبیه حقیقت است.
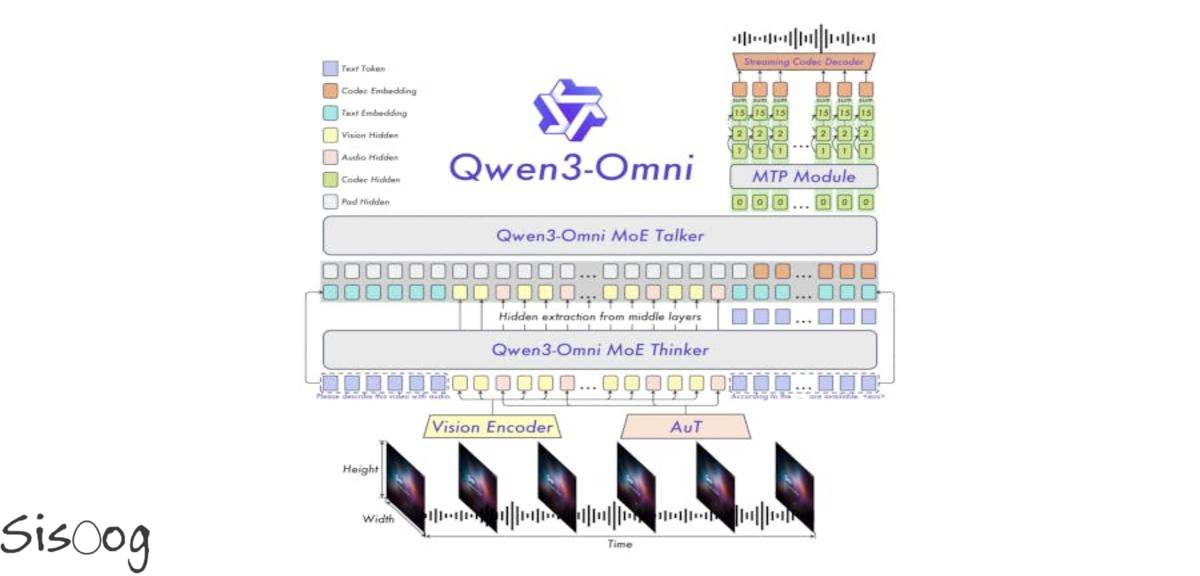
معماری Thinker-Talker و جریان داده
Qwen3-Omni از معماری «Thinker-Talker» بهره میگیرد:
- Thinker: مسئول تولید متن؛ نمایشهای سطحبالای معنایی/زبانی را تولید میکند.
- Talker: از نمایشهای سطحبالای Thinker مستقیماً تغذیه میشود و توکنهای گفتار استریمی را تولید میکند.
فرآیند تولید گفتار با تأخیر بسیار کم، بهصورت خودرگرسیو و چند مرحلهای انجام میشود:
- Talker بهصورت autoregressive یک توالی multi-codebook را پیشبینی میکند.
- در هر گام دیکود، یک MTP module «کدبوکهای باقیمانده (residual codebooks)» را برای فریم جاری خروجی میدهد.
- سپس رندرر Code2Wav موج متناظر با همان فریم را بهصورت افزایشی میسازد.
- نتیجه، تولید گفتار فریمبهفریم و استریم پایدار با تأخیر پایین است.
این جداسازی کارکردی میان «تفکر» و «صحبت کردن» اجازه میدهد مدل همزمان متن را گسترش دهد و خروجی صوتی آن را، بدون انتظار برای تکمیل کل پاسخ متنی، بهصورت پیوسته پخش کند.
چندحالتهی بومی و راهبرد آموزش

جذابیت اصلی Qwen3-Omni، همهحالته بودن در یک مدل واحد است. بهگفتهی تیم توسعه، مخلوط کردن دادههای تکحالته (unimodal) و بینحالته (cross-modal) در مراحل ابتدایی پیشآموزش متنی، برابری عملکردی بین همهی مُدالیتیها را امکانپذیر میکند؛ به این معنی که افت عملکرد ویژهی هر مُدالیتی رخ ندهد و توانمندی بینحالته بهطور محسوسی تقویت شود.
با این حال، گزارش فنی خودِ شرکت اذعان میکند که هرچند عملکرد Qwen3-Omni در انواع رسانه قوی است، کیفیت پردازش متن آن نسبت به مدل تکحالتهی Qwen3-Instruct ضعیفتر است. این نشان میدهد در عمل، حرکت از یک مدل تخصصی تکحالته به یک مدل همهفنحریف، با یک مبادلهی واقعی در بخشی از عملکرد همراه است.
کارایی، تأخیر و محدودیتها
تاکید Qwen3-Omni بر تعاملات صوتی بیدرنگ است. اعداد اعلامشده برای تأخیر، نشاندهندهی کارایی مناسب برای کاربردهای گفتوگومحور هستند. همچنین طول ورودی صوتی پشتیبانیشده تا 30 دقیقه است، که برای مکالمات طولانی یا پردازش محتوای شنیداری ممتد مفید است.
| پارامتر | مقدار/وضعیت | توضیح |
|---|---|---|
| اندازه مدل | 30B پارامتر | هر سه واریانت 30 میلیارد پارامتری هستند |
| مُدالیتیها | Text، Image، Audio، Video | ورودی چندرسانهای؛ خروجی متن و گفتار استریمی |
| معماری | Thinker-Talker | تفکیک تولید متن و گفتار |
| مسیر گفتار | MTP + Code2Wav | پیشبینی multi-codebook و سنتز افزایشی فریمبهفریم |
| تأخیر صوت | ≈ 211ms | پاسخ صوتی بیدرنگ |
| تأخیر صوت/ویدیو | ≈ 507ms | برای ورودیهای AV |
| طول ورودی صوت | تا 30 دقیقه | پردازش فایل/استریم طولانی |
| زبانهای متن | 119 | پشتیبانی چندزبانه در حالت متنی |
| ASR (بازشناسی گفتار) | 19 زبان | ورودی گفتاری |
| TTS (تولید گفتار) | 10 زبان | خروجی گفتار طبیعی |
| tool-calling | پشتیبانی میشود | ساخت دستیارهای عاملمحور (agentic) |
| محل انتشار | GitHub، Hugging Face، ModelScope | همراه با دمو در Hugging Face |
| مجوز | Apache 2.0 | مجوز باز؛ اما نه کاملاً متنباز بهمعنای قابلساخت از صفر |
برداشت سریع از اعداد بالا: تأخیرهای 211/507 میلیثانیه برای کاربردهای گفتوگومحور مناسب هستند و ورودی صوتی 30 دقیقهای انعطاف خوبی میدهد. دامنهی زبانی گسترده، Qwen3-Omni را برای سناریوهای چندزبانه جذابتر میکند.
توانمندیهای عاملمحور با tool-calling
Qwen3-Omni از «فراخوانی ابزار» (tool-calling) پشتیبانی میکند. این قابلیت امکان اجرای برنامهها/ابزارهای خارجی را فراهم میسازد تا یک دستیار عاملمحور (agentic) نه فقط دستورالعمل ارائه دهد، بلکه اقدام عملی برای تکمیل وظایف انجام دهد. این ویژگی برای خودکارسازی گردشکارها، یکپارچهسازی با سرویسها و کنترل سیستمها کاربردی است.
واریانتها، مجوز و دسترسی
Alibaba Cloud سه نسخهی سفارشی از Qwen3-Omni را منتشر کرده است. همه تحت مجوز Apache 2.0 ارائه میشوند و از طریق GitHub، Hugging Face و ModelScope در دسترساند. یک دمو نیز روی Hugging Face عرضه شده است. با این حال، مانند بسیاری از LLMها، بستهی منتشرشده همهی اجزای لازم برای «ساخت از صفر» را شامل نمیشود؛ بنابراین «کاملاً متنباز» بهمعنای دقیق محسوب نمیشود.
| نام نسخه | اندازه | محل انتشار |
|---|---|---|
| Qwen3-Omni-30B-A3B-Instruct | 30B | GitHub، Hugging Face، ModelScope |
| Qwen3-Omni-30B-A3B-Thinking | 30B | GitHub، Hugging Face، ModelScope |
| Qwen3-Omni-30B-A3B-Captioner | 30B | GitHub، Hugging Face، ModelScope |
نامگذاری نسخهها جهتگیری آنها را تا حدی القا میکند، اما جزئیات فنی متمایزکنندهی هر واریانت در متن خبر تشریح نشده است.
ملاحظات عملکردی و مبادلهها
تیم توسعه ادعا میکند Qwen3-Omni نسبت به مدلهای مالکیتی رقیب، عملکرد پیشرو دارد. با وجود این، در مقایسهی درونخانواده، گزارش فنی نشان میدهد عملکرد متنی آن از Qwen3-Instruct پایینتر است. این مشاهده با شهود مهندسی سازگار است: یک مدل همهحالته که بهطور همزمان باید در چند مُدالیتی رقابت کند، ممکن است در برخی معیارهای تکحالته نسبت به مدلهای تخصصی امتیاز کمتری بگیرد.
از سوی دیگر، سود اصلی، توان بینحالته و یکپارچگی است: یک مدل واحد که جریانهای دادهی متنی، تصویری و صوتی/ویدیویی را همبند میکند و بهکمک معماری Thinker-Talker، پاسخ گفتاری کمتأخیر میدهد. برای کاربردهای تعاملی صوتی، این مبادله اغلب پذیرشپذیر است.
Alibaba Cloud سه نسخهی سفارشی از مدل را با نامهای Qwen3‑Omni‑30B‑A3B‑Instruct، Qwen3‑Omni‑30B‑A3B‑Thinking و Qwen3‑Omni‑30B‑A3B‑Captioner در GitHub، Hugging Face و ModelScope منتشر کرده است. همه تحت مجوز آزاد Apache 2.0 عرضه میشوند؛ با این حال، همانطور که در حوزهی LLMها رایج است، این مدلها «کاملاً متنباز» بهمعنای دقیق نیستند، زیرا همهی اجزای لازم برای ساخت مدل از صفر ارائه نشده است. یک دمو نیز روی پلتفرم Hugging Face در دسترس قرار دارد.





من اون دیوونهام که وقتی بورد روشن نمیشه، ذوق میکنم؛ یعنی یه شب تا صبح قراره با منبع تغذیه و لاجیک آنالایزر عشق کنم! آدما قهوه میخورن که بیدار بمونن، ولی من بیدار میمونم تا بفهمم این بورد چرا باهام قهر کرده! زندگی من یه لوپ بینهایته بین باگ و دیباگ... با چاشنی یه کم امید و یه عالمه دیوونگی!
مقالات بیشتر

پالت | بازار خرید و فروش قطعات الکترونیک
قطعات اضافه و بدون استفاده همیشه یکی از سربارههای شرکتها و طراحان حوزه برق و الکترونیک بوده و هست. پالت سامانهای است که بصورت تخصصی اجازه خرید و فروش قطعات مازاد الکترونیک را فراهم میکند. فروش در پالت
آیسی | موتور جستجوی قطعات الکترونیک
سامانه آی سی سیسوگ (Isee) قابلیتی جدید و کاربردی از سیسوگ است. در این سامانه سعی شده است که جستجو، انتخاب و خرید مناسب تر قطعات برای کاربران تسهیل شود. جستجو در آیسی
سیسوگشاپ | فروشگاه محصولات Quectel
فروشگاه سیسوگ مجموعه ای متمرکز بر تکنولوژی های مبتنی بر IOT و ماژول های M2M نظیر GSM، GPS، LTE، NB-IOT، WiFi، BT و ... جایی که با تعامل فنی و سازنده، بهترین راهکارها انتخاب می شوند. برو به فروشگاه سیسوگ
سیسوگ فروم | محلی برای پاسخ پرسشهای شما
دغدغه همیشگی فعالان تخصصی هر حوزه وجود بستری برای گفتگو و پرسش و پاسخ است. سیسوگ فروم یک انجمن آنلاین است که بصورت تخصصی امکان بحث، گفتگو و پرسش و پاسخ در حوزه الکترونیک را فراهم میکند. پرسش در سیسوگ فرم
سیکار | اولین مرجع متن باز ECU در ایران
بررسی و ارائه اطلاعات مربوط به ECU (واحد کنترل الکترونیکی) و نرمافزارهای متن باز مرتبط با آن برو به سیکار







سیسوگ با افتخار فضایی برای اشتراک گذاری دانش شماست. برای ما مقاله بنویسید.