درک چند حسی چیست و چگونه کار میکند؟
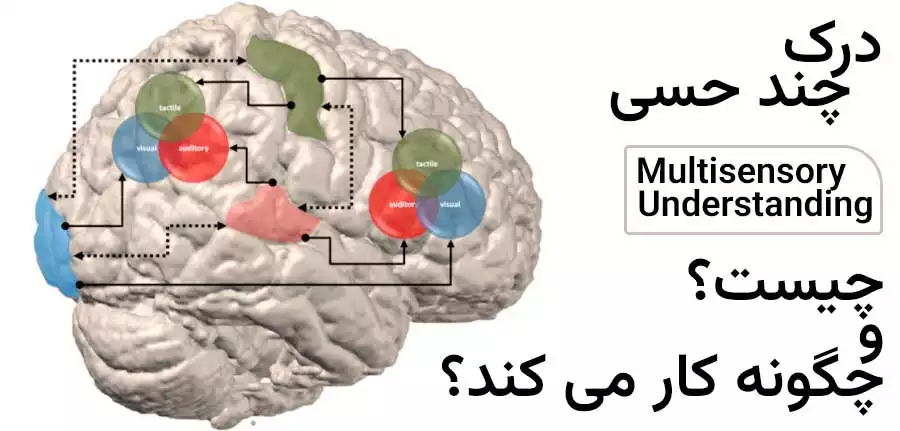
تکنیک درک چند حسی ML میتواند روابط بین دیتاهای صوتی و تصویری را یاد بگیرد تا جهان را با روشی شبیه به انسان درک کند. در این مقاله از سایت سیسوگ قصد داریم به بررسی این موضوع بپردازیم. بهطورکلی دیتاهای صوتی و تصویری، نقشی اساسی در درک انسان از دنیای اطراف خود دارند. حواس بینایی و شنوایی ما به شیوهای هماهنگ با هم کار میکنند و درک جامعی از محیط به ما ارائه میدهند. این ادغام اطلاعات شنیداری و بصری ما را قادر میسازد تا درک بهتری از رویدادها، اشیا و افراد پیرامون خود داشته باشیم.
بهعنوانمثال، وقتی فیلمی تماشا میکنیم، نهتنها شخصیتها و صحنهها را میبینیم، بلکه دیالوگها، موسیقی پسزمینه و جلوههای صوتی آن را نیز میشنویم. این ادغام حواس بینایی و شنوایی موجب افزایش احساسات عاطفی ما میشود. همچنین، به ما کمک میکند تا خط داستانی فیلم را دنبال کنیم و به تجربه کلی ما عمق میدهد.
به طور مشابه، در زندگی روزمره، ما به اطلاعات دیداری و شنیداری برای موارد گوناگونی از جمله: حرکت در محیط، تشخیص چهرهها، تفسیر ژستها و درک نشانههای اجتماعی نیاز داریم. افزایش ادغام دیتاهای صوتی و تصویری یک چالش مهم برای برنامههای بینایی کامپیوتر است. بهمنظور توسعه الگوریتمهای یادگیری موردنیاز برای درک این دیتاهای بسیار پیچیده، حجم زیادی از نمونه دیتاهای دستی موردنیاز است؛ اما تولید این نوع دیتاها بسیار وقتگیر و پرهزینه است و همچنین، امکان وجود خطا نیز در آنها زیاد است.
شاید برای شما مفید باشد: آموزش آردوینو از 0 تا 100

روش CAV-MAE (انکودر خودکار سمعی و بصری) چیست؟
باتوجهبه کاربردهای مهمی که این فناوری میتواند داشته باشد و علاقه زیادی که به ترکیب دیتاهای صوتی و تصویری وجود دارد، واضح است که دیتاهایی که به صورت دستی وارد میشوند نمیتوانند به اندازه کافی بزرگ شوند. قبل از اینکه امکان استفاده از دیتاها در مقیاس وب وجود داشته باشد، باید روشهای جدیدی برای گسترش الگوریتمها ایجاد شود.
یکی از این روشها بهتازگی توسط تیمی به رهبری محققان MIT CSAIL پیشنهاد شده است. در این راستا، آنها نوعی شبکه عصبی به نام انکودر خودکار سمعی و بصری (CAV-MAE) ایجاد کردهاند که میتواند مدلسازی روابط بین دیتاهای صوتی و بصری را یاد بگیرد و این کار را به روشی شبیه به انسان انجام میدهد. بهعلاوه، از روشهای یادگیری خود نظارتی بهجای دیتاهای برچسبگذاری شده دستی استفاده میکند.
مراحل روش CAV-MAE
روش CAV-MAE دو مرحله مجزا دارد. در مرحله اول، یک مدل پیشبینی کننده به طور جداگانه 75 درصد از دیتاهای صوتی و تصویری را پوشش میدهد، سپس 25 درصد باقیمانده را رمزگذاری میکند. در مرحله بعد، انکودرهای صوتی و تصویری سعی میکنند تا دیتاها را معنا کنند، پس از آن الگوریتم تلاش میکند که ناقصی های دیتاهای ماسک شده را پیشبینی کند. اختلاف بین دیتاهای پنهان شده واقعی و پیشبینی کننده برای محاسبه ضرر استفاده میشود و سپس برای کمک به مدل یادگیری و بهبود پیشبینیها استفاده میشود.
این فرایند تنها بخشی از اطلاعات مربوط به ترکیب دیتاهای سمعی و بصری را در بر میگیرد و این اطلاعات بهخودیخود کافی نیستند؛ بنابراین نتیجه مرحله اول، ایجاد یک مدل Contrastive Learning بود. contrastive learner به دنبال این است که نمایشهای مشابه را نزدیک به یکدیگر قرار دهد. این کار را ابتدا با ارسال جداگانه دیتاهای صوتی و تصویری به انکودرهای خود انجام میدهد، سپس نتایج را به یک انکودر مشترک ارسال میکند. همچنین، این انکودر مشترک اجزای صوتی و بصری را از هم جدا نگه میدارد که این کار برای تعیین اینکه کدام بخش از هر نوع دیتا با یکدیگر مرتبط هستند، انجام میشود.

شاید برای شما مفید باشد: آموزش رزبری پای از مقدماتی تا پیشرفته
برای تأیید این روش، تیم محققان MIT CSAIL دو مدل جداگانه ارائه دادند. مدل اول فقط از یک انکودر ماسک شده تشکیل شده بود و مدل دیگر فقط از یادگیری متضاد استفاده میکرد. نتایج این آزمایش با نتایج CAV-MAE مقایسه شد. این مقایسه نشان داد که روش CAV-MAE بهتر است؛ زیرا سینرژی بین تکنیکها را نشان میدهد. در واقع، روش CAV-MAE حتی با نتایجی که هنگام اجرای مدلهای نظارتی پیشرفته در وظایف طبقهبندی رویدادهای صوتی و تصویری مشاهده میشود، میتواند رقابت کند. علاوه بر این، مشخص شد که روشهای تیم محققان MIT CSAIL با روشهایی که از منابع محاسباتی بیشتری استفاده میکنند، یکسان یا حتی بهتر از آنها عمل میکنند.
کابردهای روش CAV-MAE
روش CAV-MAE برای کاربردهای چندوجهی یکقدم به جلو برداشته است. محققان پیشبینی کردهاند که این روش در بسیاری از زمینهها از جمله ورزش، آموزش، سرگرمی، وسایل نقلیه موتوری و ایمنی عمومی کاربرد خواهد داشت. همچنین، آنها معتقدند که در آینده، روشهایی فراتر از صدا و تصویر گسترش خواهد یافت.
منبع: hackster.io






پالت | بازار خرید و فروش قطعات الکترونیک
قطعات اضافه و بدون استفاده همیشه یکی از سربارههای شرکتها و طراحان حوزه برق و الکترونیک بوده و هست. پالت سامانهای است که بصورت تخصصی اجازه خرید و فروش قطعات مازاد الکترونیک را فراهم میکند. فروش در پالت
آیسی | موتور جستجوی قطعات الکترونیک
سامانه آی سی سیسوگ (Isee) قابلیتی جدید و کاربردی از سیسوگ است. در این سامانه سعی شده است که جستجو، انتخاب و خرید مناسب تر قطعات برای کاربران تسهیل شود. جستجو در آیسی
سیسوگشاپ | فروشگاه محصولات Quectel
فروشگاه سیسوگ مجموعه ای متمرکز بر تکنولوژی های مبتنی بر IOT و ماژول های M2M نظیر GSM، GPS، LTE، NB-IOT، WiFi، BT و ... جایی که با تعامل فنی و سازنده، بهترین راهکارها انتخاب می شوند. برو به فروشگاه سیسوگ
سیسوگ فروم | محلی برای پاسخ پرسشهای شما
دغدغه همیشگی فعالان تخصصی هر حوزه وجود بستری برای گفتگو و پرسش و پاسخ است. سیسوگ فروم یک انجمن آنلاین است که بصورت تخصصی امکان بحث، گفتگو و پرسش و پاسخ در حوزه الکترونیک را فراهم میکند. پرسش در سیسوگ فرم
سیکار | اولین مرجع متن باز ECU در ایران
بررسی و ارائه اطلاعات مربوط به ECU (واحد کنترل الکترونیکی) و نرمافزارهای متن باز مرتبط با آن برو به سیکار







سیسوگ با افتخار فضایی برای اشتراک گذاری دانش شماست. برای ما مقاله بنویسید.